前回の記事で、会社のホームページURLを取得するため、Google検索結果を利用しました。
Google検索結果を取得するニーズは高いと思われますが、割とコツが必要と感じたので、今回は、PythonでWebスクレイピングしてGoogle検索トップのURLを取得する方法について、解説したいと思います。
Google検索トップのURLを取得する処理の流れは次のようになります。
1.Google検索のキーワード検索URLにキーワードを付けてアクセスする
2.Google検索実行結果を取得し、検索結果のURL一覧を絞り込む
3.絞り込んだURLから不要と思われるURLを省く
4.リストの一番前に入っているURL(=トップURL)を出力する
これらをプログラムで表すと次のようになります。
ではプログラムを見ていきましょう。
事前に必要なライブラリをpip installしておきます。
pip3 install requests
pip3 install beautifulsoup4
まずは、ライブラリのインポート部分です。
行頭の「# -*- coding: utf-8 -*-」は、プログラム内で日本語を利用する際に必ず記入します。
2行目の「requests」は、PythonでHTTPリクエストを実行する場合に必要です。
3行目の「bs4」は「BeautifulSoup」の略で、HTTPリクエストにより得られたHTMLファイルを処理するライブラリです。bs4から「BeautifulSoup」クラスを読み込んでいます。
4行目の「re」は、正規表現を利用した文字列置換を行うためにインポートしています。
続いて、6行目から26行目は「get_google_search_top_url」メソッド定義となります。
こちらで定義したメソッドを28行目から37行目のメイン処理で呼び出しています。
「get_google_search_top_url」メソッド定義を見ていきましょう。
6行目でメソッドの引数を指定します。引数は下記2つです。
・[リスト型]検索ワード(必須)
Google検索したいワードをリスト型で渡します。今回のメイン処理では「タピオカミルクティ」「発祥の地」の2つを渡しています。
・[リスト型]URL除外文字列(任意)
Google検索トップのURLを取得する上で邪魔になりそうなURLを除外するために用意しました。こちらは必須ではないので、指定しなくても良いです。今回のメイン処理では、トップURLとして取得したくないURLに含まれる「google」「wikipedia」の2つを渡しています。
続いて、7行目では引数で受け取ったリストを「+」で結合した文字列に変換します。今回の場合は、「タピオカミルクティ+発祥の地」となります。Google検索のURLではスペース区切りの検索ワードが「+」区切りで表現されます。8行目でGoogle検索のURLを作成しています。
9行目で作成したURLにHTTP接続し、結果を取得、10行目でBeautifulSoupに渡しています。
次に、取得したHTMLファイルからdivタグの中にあるアンカータグを読み出し、一つずつループで処理をしていきます。
まず、11行目でメソッドの戻り値となる結果文字列を定義します。初期値は空とします。
12行目でループを定義します。13行目でアンカータグのhref属性の値を取得します。
14行目でhref属性が「/url?q=」という文字列から始まっているもののみを対象にします。Google検索結果のリンクは「/url?q=」から始まっているからです。それ以外のリンクをふるいにかけます。
15行目から21行目で、URL除外文字列を含むURLをふるいにかけます。URLが除外リストにある文字列を含む場合、forをcontinueして次のURLを処理します。
除外リストにある文字列を含まない場合は、22行目から25行目の処理を実行し、ループを終了します。
22行目では、URLから「/url?q=」を除去して「https://」から始まる文字列に変換します。
23行目では、Google検索結果のURLの末尾に付加される「&sa=U」から始まる余分な文字列を除去しています。
24行目で戻り値に代入して、25行目でforループを抜けます。トップURLを取得したいので1番はじめに見つかったURLを戻り値にします。
26行目で、戻り値を返してメソッド終了です。
28行目から37行目は、メイン処理で、引数に渡すデータを定義した後、「get_google_search_top_url」メソッドを呼び出しています。
本プログラムの実行結果は下記のようになります。
Google Search Top URL = https://chisou-media.jp/posts/3247
Webブラウザで「タピオカミルクティ 発祥の地」を検索したところ、Wikipediaがトップに出ましたが、除外しているので、その次のサイトが本プログラムの結果と同一のサイトであることが確認できました。
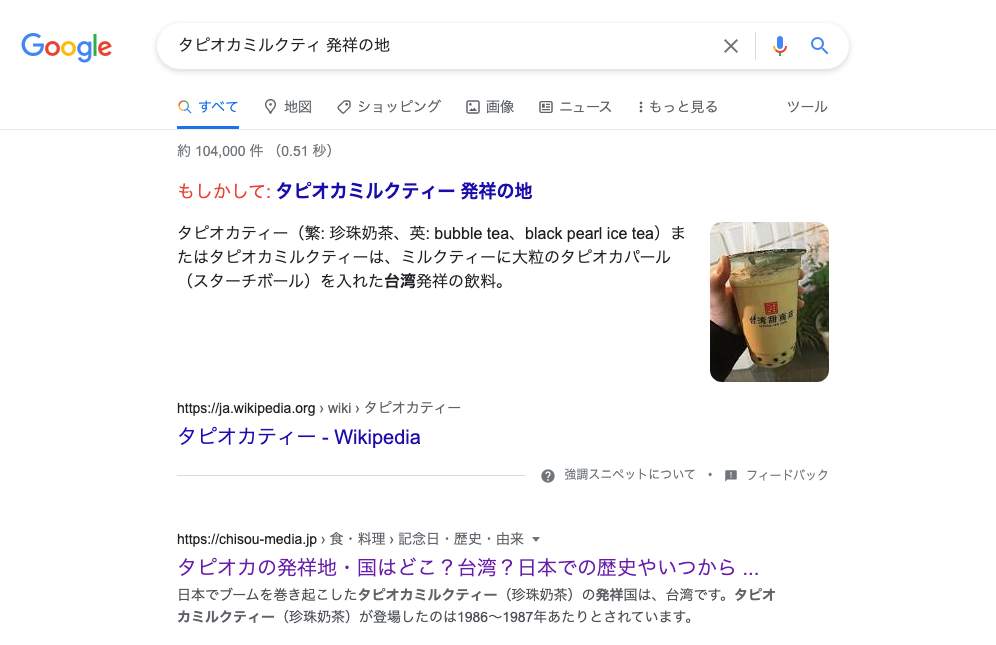
Webスクレイピングの注意事項として、自動生成される文字列を目印にしないことです。
例えば今回のプログラムでは、Google検索結果のHTML文字列内に「<div class=”oySJpc”」という文字列があり、Google検索結果毎に付与されているため、一見するとこの文字列を利用すれば簡単にGoogle検索結果のURLを取得できそうに思えます。
しかし、この「oySJpc」という意味のなさそうな文字列は自動生成されている可能性が高く、一定期間中は有効でも、数日〜数カ月後には別の文字列に変わっていることが多いです。
実生活でも道を覚えるときは、移動する可能性のある車を目印にはしないでしょう。
Webスクレイピングでは、Webサイトの構成が変更されればスクリプトの作りを変えなければなりませんが、なるべく長期間変更の必要のないように構成すべきでしょう。
コメント