
前回の記事で画像処理についてまとめましたが、今回、ついにAIに手を出しました。

AIは、5年ぐらい前にChainerというフレームワークを使って少し触っていたことがありましたが、5年のブランクを経て、今主流のTensorFlow2を触ってみました。
以前と比べて情報も多く、始めやすい環境になっていると思います。
今回の記事は、TensorFlow(テンソルフロー)のチュートリアルとなっているMNISTのプログラムを少し弄って、自分の手書き数字を認識してみました。
MNISTとは
MNIST(Modified National Institute of Standards and Technology)は、手書き数字画像の大規模データベースです。
0〜9の数字を手書きした、28×28ピクセルの画像が大量にあり、機械学習やAIの学習に利用できるように公開されています。
TensorFlowを始めた人が、Hello World的に利用できるようになっており、とりあえずMNISTが動いたから環境構築オッケーという感じでスルーされがちですが、今回はMNISTを使って遊びます。
TensorFlowにおけるMNISTのチュートリアルでは、TensorFlowをインストールした端末で、以下の流れのプログラムを動かします。
- MNISTデータベースをダウンロードする
- 学習モデルを作成し、MNISTのトレーニングデータで学習を行う
- 学習が完了したモデルで、テストデータを検証し、正答率を出力する
ここでは、チュートリアルのプログラム解説は割愛しますが、正答率は97%程度になると思います。
そして、ふむふむ、いい感じだね。となってスルーされます。笑
今回はスルーせず、本当に数字の認識ができるのか確かめてみます。
MNISTのモデルを保存して数字識別機を作る
まず、MNISTを使って数字識別機を作ります。
具体的には前章の1、2を行い、学習済みのモデルを保存します。
保存した学習済みのモデルは、別のプログラムで読み込んで識別機として利用することができます。
下記のプログラムでは、MNISTのチュートリアルのモデルを少し改良していて、正答率は99%ぐらいです。
このプログラムを実行すると、カレントディレクトリに「mnist_model」というディレクトリができます。これが数字識別機です。
手書き数字作成プログラム
続いて、手書き数字作成プログラムを作成します。
処理の流れは以下のようにします。
- 数字をいくつか手書きする
- 認識ボタンをクリックする
- 数字を一つ一つ検出して画像化
- 数字識別を実行
- 識別結果を表示する
プログラムは下記です。
このレベルの高度なプログラムが200行未満で出来てしまうことに技術の進歩を感じます。
作成した数字識別機を実行してみる
mnist_play.pyを実行すると、横に細長いウインドウが立ち上がります。

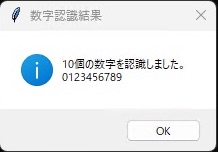
白い部分にマウスを使って数字を書き、認識ボタンを押下すると、

無事識別出来ました。これでHello World完了です。
AI五目並べを作ってみました。


コメント